Outline
① Examples
② Basic Concepts
③ Scheduling Criteria
④ Scheduling Algorithms
⑤ Multiple-Processor Scheduling
⑥ Thread Scheduling
⑦ Linux Scheduling
⑧ Algorithm Evaluation
① Examples
TV 스케줄링
가족이 TV 보는 시간을 어떻게 할당할 것인가?
CPU 스케줄링
프로세스가 CPU를 사용하는 시간을 어떻게 할당할 것인가?
② Basic Concepts
● 스케줄링 기본 규칙
I/O Bound 프로세스에 더 높은 우선순위 부여
=> 프로세스가 ready 큐에서 기다리는 평균 waiting time을 최소화함
● CPU 스케줄러
CPU가 유휴상태가 될 때마다 운영체제는 ready 큐에 있는 프로세스들 중 하나를 CPU에 할당
● CPU 스케줄링이 결정되는 상황
1. running -> waiting (비선점)
2. running -> ready (선점)
3. waiting -> ready (선점)
4. terminates (비선점)
● 커널에서의 Preemption
1. system call
우선순위 B > A일 때
1) Preemptive kernel
-> Preemption을 허용해서 A 프로세스의 SYSTEM CALL을 중단시키고 B 프로세스 우선 수행
2) Non-preemptive kernel
-> A 프로세스의 SYSTEM CALL이 끝나길 기다리고 B 프로세스 수행
2. HW Interrupt handler
-> 빠르게 무조건적으로 수행되어야 하므로 preemption 허용 안함
● 디스패처 (Dispatcher)
CPU의 제어를 단기 스케줄러가 선택한 프로세스에게 넘겨주는 모듈
1) context switch
2) 사용자 모드로 전환
3) 프로그램을 다시 시작하기 위해 user program의 적절한 위치로 이동
● Dispatcher Latency
디스패처가 하나의 프로세스를 정지하고 다른 프로세스의 수행을 시작하는데까지 소요되는 시간
③ Scheduling Criteria
● 스케줄링 기준 (Scheduling Criteria)
1. CPU 이용률 (Utilization)
-> CPU 최대한 바쁘게 유지
2. 처리량 (Throughput)
-> 단위 시간 당 완료된 프로세스 개수
3. 총 처리시간 (Turnaround time)
-> 프로세스 완료 시간 - 요청 시간
4. 대기 시간 (Waiting time)
-> ready 큐에서 기다린 시간
5. 응답 시간 (Response time)
-> 하나의 요구를 제출한 후 첫 번째 응답이 시작되는데까지 걸리는 시간
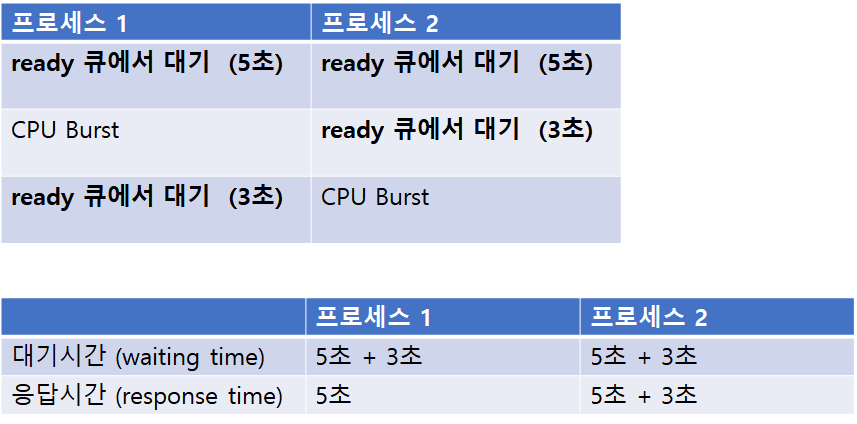
● 최적화 기준
1. 최대화
-> CPU 이용률, 처리량
2. 최소화
-> 총 처리시간 (Turnaround time), 대기 시간 (waiting time), 응답 시간 (response time)
④ Scheduling Algorithms
● FCFS (First-Come, First-Served)
-> 먼저 들어온 프로세스에게 더 높은 우선순위 부여.
-> 프로세스가 들어온 순서에 따라서 average waiting time이 달라짐.
-> 전체 프로세스 수행 시간은 동일.
-> 짧은 프로세스가 긴 프로세스 뒤에서 기다리는 현상인 convoy effect가 발생할 수 있음.
-> CPU burst가 짧은 i/o bound process에게 우선순위를 높게 주어서 convoy effect 제거 가능.
Ex) CPU Burst time: P1 = 24, P2 = 3, P3 = 3일때,
1) P1, P2, P3 순서 : Average waiting time = (0 + 24 + 27) / 3 = 17
2) P2, P3, P1 순서 : Average waiting time = (6 + 0 + 3) / 3 = 3
● SJF (Shortest-Job-First)
가장 짧은 Cpu burst length를 갖는 프로세스에게 높은 우선순위 부여.
1. Non-preemptive
-> 새로 도착한 task의 cpu burst length가 먼저 수행된 tsak의 cpu burst length보다 짧아도
-> 먼저 수행된 task가 끝나기를 기다림.
2. Preemptive
-> 새로 도착한 task의 cpu burst length가 먼저 수행된 task의 “남은 시간”보다 짧을 경우
-> 새로운 task로 context switch. Average waiting time을 최소화 할 수 있음.
Ex) CPU Burst time: P1 = 7, P2 = 4, P3 = 1, P4 = 4,
Arrival time: P1 = 0, P2 = 2, P3 = 4, P4 = 5일때
1) Average waiting time of Non-preemptive: (0 + (8-2) + (7-4) + (12-5)) / 4 = 4
2) Average waiting time of Preemptive: ((11-2) + (5-4) + 0 + (7-5)) / 4 = 3
문제점
기아 (starvation): 높은 우선순위를 가진 프로세스들이 꾸준히 들어와서 낮은 우선순위 프로세스들이 CPU를 얻지 못함
해결
노화 (aging): 오래동안 대기한 프로세스들의 우선순위를 점진적으로 증가시킴
CPU 버스트 길이 예측
Exponential Averaging
-> 오래된 작업일수록 낮은 가중치 부여, 최신 작업일수록 높은 가중치를 부여하여 다음 CPU burst의 길이를 예측한다.

● Round-Robin
시간 할당량 (time quantum)만큼 실행 후 프로세스 변경
SJF에 비해서
turnaround time : 더 긺
response time : 더 짧음
q 크면
-> FIFO (프로세스 잘 안바뀜)
q 작으면
-> context switch 자주 발생해서 overhead 증가 (프로세스 자주 바뀜)
-> context switch overhead와 response time의 trade-off
※ 각 프로세스는 (n-1) * q 시간 이상 대기하지 않음
● Multilevel Queue
포그라운드, 백그라운드 프로세스로 구분
ready 큐를 다수의 별도의 큐로 분류
각 큐는 자신의 스케줄링 알고리즘을 가짐
큐 간 스케줄링 알고리즘 존재

Fixed priority preemptive scheduling
batch process 실행 중에 interactive editing process가 ready 큐에 들어가면 batch process 선점됨
● Multilevel Feedback Queue
다단계 큐: 프로세스 이동 (x)
다단계 피드백 큐: 프로세스 이동 (o)
프로세스들을 CPU 버스트 성격에 따라 구분
CPU 시간 많이 사용 -> 낮은 우선순위 큐로 이동
오래 대기한 프로세스 -> 높은 우선순위 큐로 이동
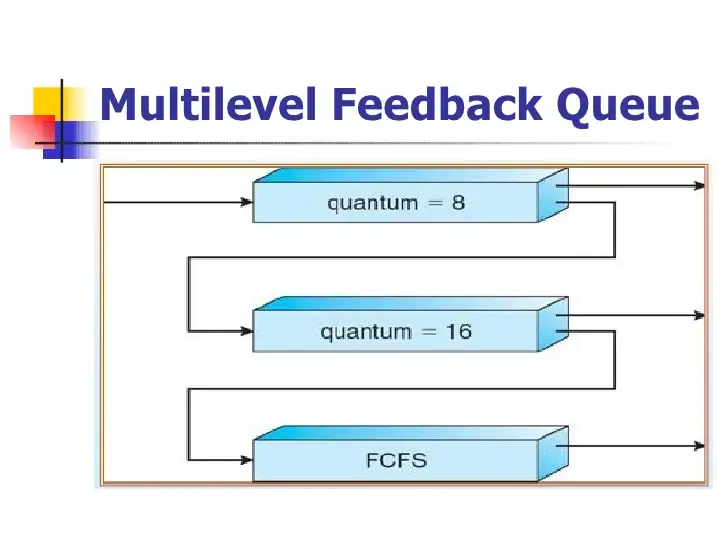
quantum = 8에서
CPU burst 8 이하 -> 끝
CPU burst 8 초과 -> 다음으로 이동
quantum = 16에서
CPU burst 16 이하 -> 끝
CPU burst 16 초과 -> 다음으로 이동
⑤ Multiple-Processor Scheduling
1. Symmetric multiprocessing
-> 각각의 프로세서는 자신만의 스케줄링 결정을 내림
-> Master-slave relationship 없음
2. Asymmetric multiprocessing
-> 하나의 프로세서만이 시스템 자료구조에 접근, data 공유의 의무를 완화시킴
-> Master-slave relationship 있음
● Process affinity
1. Soft affinity
-> operating system이 프로세스를 affinity 관계에 있는 CPU에 할당하려고 하지만 보장은 되지 않음
2. Hard affinity
-> operating system이 프로세스를 affinity 관계에 있는 CPU에 할당하는 것을 보장함.
-> 프로그래머가 특정 CPU에 할당되도록 operating system에 system call 요청.
● Load balancing
특정 CPU에 일이 몰리지 않도록 적절히 분배
1. Push migration
-> specific한 task가 프로세서들을 확인, 불균형이 발견됐을 경우 다른 CPU에게 작업을 나눠 줌(push)
2. Pull migration
-> idle한 CPU가 바쁜 CPU의 일을 가져옴(pull)
⑥ Thread Scheduling
user thread는 별도로 스케줄링 되는 개체
LWP (Light Weight Process)를 통해 간접적으로 kernel thread와 연결
1. Local Scheduling
-> 쓰레드 라이브러리가 어떤 쓰레드를 이용 가능한 LWP에 넣을 것인지 결정
-> 프로세스 경쟁 범위 (Process-contention Scope): 동일한 프로세스에 속한 쓰레드들 사이에서 CPU 경쟁
2. Global Scheduling
-> 커널이 어떤 커널 쓰레드를 다음에 실행시킬 지 결정
-> 시스템 경쟁 범위 (System-contention Scope): CPU 상에 어느 커널 쓰레드를 스케줄링 할 것인지 결정

⑦ Linux Scheduling
리눅스
각 클래스별로 특정 우선순위 부여받는 스케줄링 클래스 기반
1. real-time class
-> 우선순위: 0 ~ 99
-> 항상 높은 우선순위 프로세스 선호
2. conventional class
-> 우선순위: 100 ~ 139
-> CFS (Completely Fair Sharing)
● CFS (Completely Faire Sharing)
-> 임의의 한 시점에서 봤을 때 프로세스 진행률은 항상 일정한 비율 유지
-> CPU는 하나이므로 특정 시간에서 실행할 수 있는 task는 오직 하나
-> 불가능
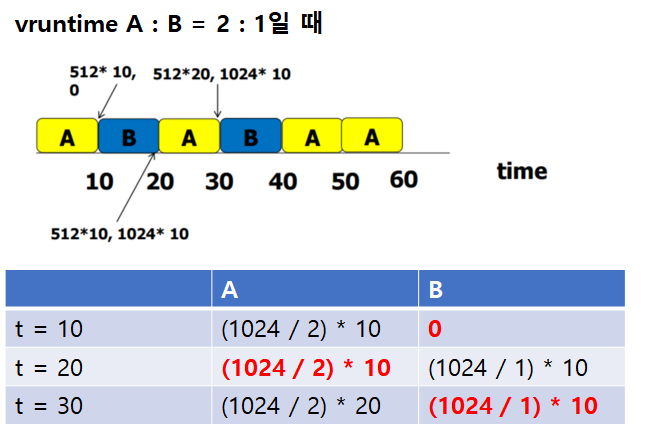
● virtual time mechanism
다음 수행할 작업으로 가장 낮은 vruntime값을 가지는 작업을 선택.

⑧ Algorithm Evaluation
1. 결정론적 모델링 (Deterministic Modeling)
-> 사전에 정의된 특정한 work load를 받아들임
-> work load에 대한 각 알고리즘의 성능 정의
-> 간트 차트 사용
※ Predetermined work load 예시
| Process | Burst Time |
| P1 | 24 |
| P2 | 3 |
| P3 | 3 |
2. 큐잉 모델 (Queueing Models)
-> 상황에 따라 실행되는 프로세스들 매번 바뀜
-> 수학적으로 분석
-> 복잡한 알고리즘, 분포와 관련된 수학적 분석 어려움
-> 실제 시스템의 근사치이며, 연산 결과의 정확성에 의심의 여지가 있음
3. 모의실험 (Simulation)
-> 실제 시스템의 연속적 사건들 사이 관계 때문에 부정확할 수 있음
4. 구현 (Implementation)
-> 가장 정확함
-> 비용이 많이 듦
'CS 공부 > 운영체제' 카테고리의 다른 글
| Chapter 8. Deadlocks (0) | 2021.09.23 |
|---|---|
| Chapter 6, 7 Process Synchronization (0) | 2021.09.23 |
| Chapter 4. Threads & Concurrency (0) | 2021.09.17 |
| Chapter 3. Process Concept (0) | 2021.09.16 |
| Chapter 2 (0) | 2021.09.16 |